Jan 21, 2017
Never under estimate the power of a broken testsuite
11 min read
In the course of my very little participation{:target="_blank"} in the opensource world, i have come by a recurrent theme.
This theme has happened to be the default route i take whenever i run git clone on a package on Github.
Truly, this process have also been applied to code i wrote months ago but couldn't really figure out a certain part of it.
A little side story
Every now and then, we programmers take an interest in a certain library, then decide we'd go through it's codebase some day. That day finally comes through, we turn off the lights, put on our headsets with some J Cole or Ab-Soul music on repeat, open up our IDE. Then the zone gets entered.
I swear it is like teleportation.
But i have always had problems with this method. I sure get in the zone, that's a no brainer. But chances are the codebase would be complex to some degree and fairly hard to grok. Maybe there's a lot of small classes - which is a good thing by the way - but i find myself navigating from file to file (class definitions) so often it starts to feel like a game - how many files can you open in 5 minutes ?.
Or maybe there's just a lot of smartness going on in the library. I am afraid i am not a top programmer.
Encountering high level of smartness in a codebase is usually my excuse for hitting ALT + F4 in other to spend some time on Genius{:target="_blank"} or some other place.
This smartness reduces my ability to teleport to deeper parts of the zone the same way darkness reduces Shawna Baez's (Peek-a-Boo) teleporting ability. The Flash, anyone ?
But i came across a technique some months ago to overcome situations like this. Isn't that what programmers do ? overcome/hunt down bugs.
This technique is called Learning Tests. Yup, learning tests. _Not Learning tests as in how to write unit tests (or any other type as a matter of fact) _ but Learning tests as in tests you write in other to gain an insight into the API, functionality, quirks and innner workings of a library.
I found this idea some months ago in the Clean code <sup>[0]</sup> book by Uncle Bob and the object mentor guys. Funny enough, I first read this book in 2015 - every one was recommending it to beginners who have gotten past "Hello World" programs. It did make sense back then but i read it again around last October - more than a year after the first read. And oh boy, I found this hidden gem.
So how does Learning Tests Work
This was described in the chapter titled Boundaries written by James Grenning.
Learning the third-party code is hard. Integrating the third-party code is hard too. Doing both at the same time is doubly hard. What if we took a different approach? Instead of experimenting and trying out the new stuff in our production code, we could write some tests to explore our understanding of the third-party code. Jim Newkirk calls such tests learning tests. In learning tests we call the third-party API, as we expect to use it in our application. We’re essentially doing controlled experiments that check our understanding of that API. The tests focus on what we want out of the API.
So basically, it works by writing tests for the library in other to see it in action and verify that it does it's stuff the way you expected it to.
How do i rewrite a test suite (albeit a minimal test suite) for something that already has a test suite ?. Sounds crazy ? No, it is crazy or better still it sounds like recursion. I do a lot of plain dumb things but this ?.
Learn the rules like a pro, so you can break them as an artist - Pablo Picasso
How i do this
Having understood the idea behind Learning tests, i decided to break the rules in other to reduce the verbosity (tests rewrite) while still getting the desired results.
TL;DR
So what do i do ? I simply negate the assertions in the test suites. Yeah, all of them. This takes me to the red bar but i get to be able to fix each test's assertion(s) by making the tests pass again but i read the line of code that has to do with each assertion.
Long Explanation
But not really long.
I usually start off by creating a new git branch. It is always called fiend.
git clone [email protected]/cool/lib.git
git branch fiend && git checkout fiend
I never merge
fiendintomaster. Never ever. But i sure mergemasterintofiendas the main goal is fully understanding the library or a certain part of the library or a certain part of the library. This makes a lot of sense asfiendwould always have the latest copy of and i can break stuffs terribly without giving a shit.
The second step is actually the meat of the process but it is the longest. This is where i get to mercilessly break the test suite.
I have found out this works pretty well if the library is well tested. Well tested can mean different things. So for me, well tested - in a library's scope - means there are a lot of unit tests - a lot - and a couple tests that verify they work as expected when this units are brought together.
So let's assume the library i am trying to read it's source code is a library for hydrating data it reads from a certain place
(can be an xml/json file, a data stream, or weirdly enough from an HTTP request) into some set of objects that define the data.
Say it can convert a persons node in the data into a PersonCollection which has it values as a collection of Person objects.
The contents of the readme file or online doc should read something like this
<?php
$parser = new DataParser(new XmlStrategy('file.xml'));
$compiler = new Weird\Lib\Compiler($parser);
$compiler->doWeirdStuff();
$personsCollection = $compiler->toCollection();
Ok, so from this, i know there's a Compiler that takes in a Parser but the Parser is also dependent on a Strategy implementation - i should be
able to read from a JSON file, or a file stream, or an HTTP request, so ideally the library would have a JsonStrategy, StringLoaderStrategy
or even an IncomingRequestStrategy
I'd usually start from the first line of code.
That is the DataParser. But hold up, DataParser relies on XmlStrategy.
XmlStrategy seems like a nice place to start rather than DataParser.
This again boils down to the fact that the library has a tests that verify it's components work in units.
I open up the file that houses the tests for XmlStrategy - usually XmlStrategyTest.
Then for every of it's test method - test*, i change the assertion(s) contained within.
For instance, a test may contain an assertTrue assertion, i would convert the assertion to an assertFalse.
If the test contain an assertion called assertEquals with a local [] variable defined which was passed into the assertion,
i would tweak that [] variable to get the tests failing.
Anything to get the tests for XmlStrategy failing must be awefully done.
Then i invoke phpunit from the cli.
phpunit --colors="always" tests/Paser/Strategy/XmlStrategy.php
I know that is going to give me the red bar. But i don't care. I just don't. What i care about is knowing the tests failed and i have made wrong assumptions on the usage/API of the library
It was hard getting into this mindset and i still get fuzzy about this occasionally.
Then i disect the test suite for the XmlStrategy one after the other. This is usually done by appending --filter to phpunit's invocation.
# let's assume the test suite has one of it's test named testReturnedValues.
# We can run only that test with
$ phpunit --colors="always" tests/Paser/Strategy/XmlStrategy.php --filter='testReturnedValues'
If you like hard work, you can manually add
$this->markTestSkipped()to each test in the file except the one currently being tackled.
Why do this ? The main reason i do is to prevent distractions. If i am to really take this one test at a time, i have to turn off external disturbances. I don't want to see errors for the test i am not interested in. That would kill my morale. So i get to see the stack trace for only this particular test.
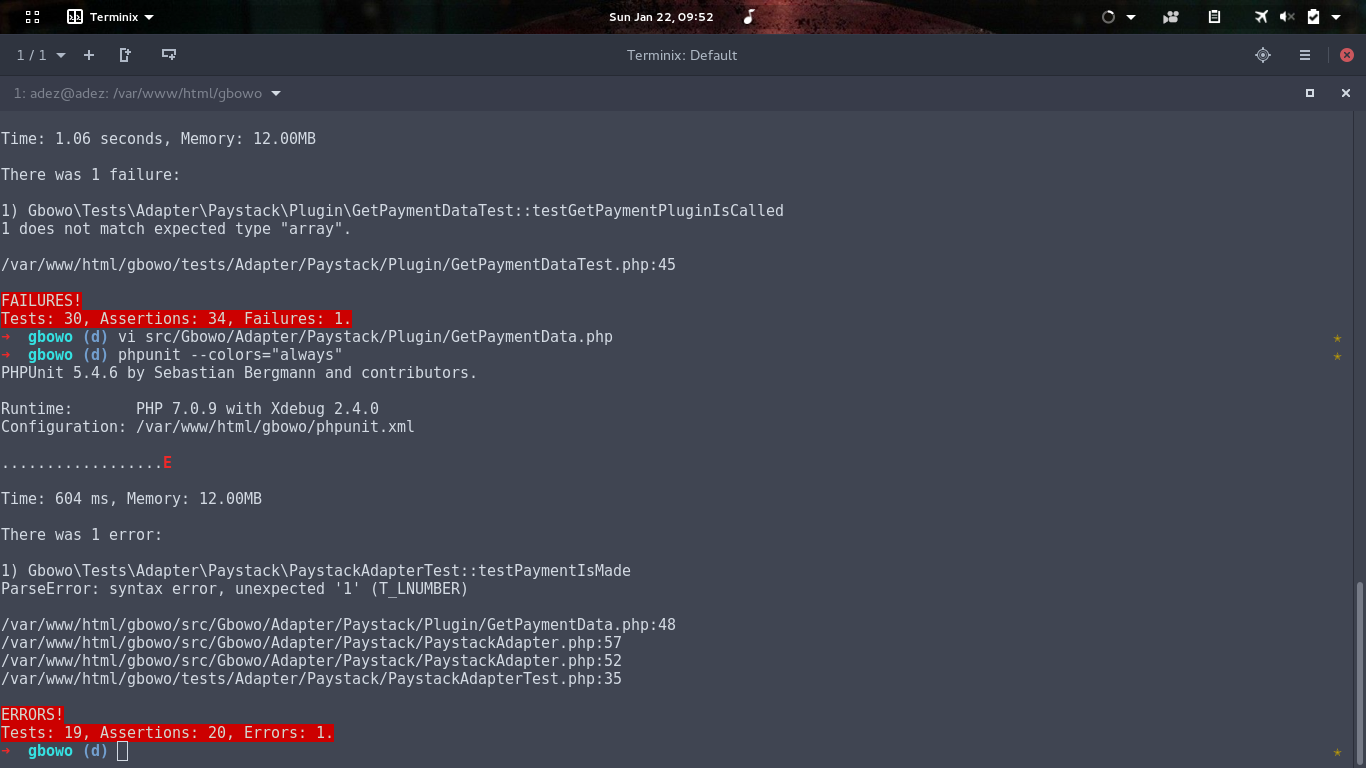
Ideally, it wouldn't be a parse error. I had to dig into some file to make something fail as an example.
The screenshot above is all i need to understand that particular test. I get the way the test was executed. What gets called ? . What gets called first ? What caused the failure ?. Then i start digging my way by going through each portion of the files in the stack trace that deals with the current test.
-
I navigate to the line number shown in the stack trace.
-
Scroll back to the constructor method to check if any thing was set up - like some array or bootstrap call(s).
-
If it is an object, you are doing it wrong. You should be in the object's test suite not the one you currently are in.
If there are bootstrap calls in the constructor that do not deal with any other object or standalone function that has it's own tests - outside of
XmlStrategy-, you are good to do. And they should be fairly easy to understand anyways.
I do this for the testReturnedValues test, the repeat for all other test in the file but only after i understand
what testReturnedValues does and i have reverted the assertion(s) to the passing implementation.
I repeat this process for the DataParser class - by now i have an understanding of XmlStrategy .
Then move to the Compiler. Unit by unit, i climb Mountain Everest.
Caveats
If at some point in the Compiler, there is a setBaz method which takes a Baz object, I pause. Repeat the process for the Baz object.
Though there is an exception here, most times when there is a setBaz method,
it most likely is an optional behaviour. So the way i look at this is in two ways ;
-
If
Bazis a part of the library, i go through it's tests and source code. -
If
Bazisn't part of the library, i skip through it and just skim through the documentation for the external library that containsBaz. A prime example of this would beEventDispatcherInterfacefrom Symfony's event dispatcher orLoggerInterfacefrom PHP-FIG.
The case for EventDispatcherInterface makes a lot of sense in this situation.
The lib might decide to give you the option to fire events everything it reaches a critical part in it's operation, say a dataParsed event or beforeHydration and afterHydration.
I don't really want to bother myself with details of that.
All i care to know is i can attach listeners for those event on the dispatcher which gets attached in the setEventDispatcher method.
The entire pub/sub <sup>[1]</sup> is not a core domain of the library, just some random stuff i can do with the library.
Like i can get away without attaching a dispatcher.
The rule here is Object under deconstruction's dependency. Who owns the dependency ?
Last words
This takes a lot of time but i dare say i have used Learning tests multiple times in the last few months and they have helped me a lot reading opensource code - or stuffs i didn't write.
You can read through a library without learning tests but in the little story i described above, it doesn't work for me. Learning tests fits my programming mental model.
And moving forward (till the day i am on some Linus Torvalds level), i'd continue making use of Learning tests.
I hope you do find this article helpful.
Footnotes
[0] This book is a gem. You should read it if you haven't.
[1] Pub/sub or Observer pattern.