Jul 24, 2017
Diving deep into net/http : A look at http.RoundTripper
9 min read
I have written quite a bit on HTTP.
And this blog post is just yet another one that talks about another interesting
concept in the way Go deals with HTTP and how it makes HTTP related stuffs
even much more fun.
In this post, I would be covering what Round tripping is, it's applicable usecases and a tiny demo that shows it's application.
This concept I want to talk about is called Round tripping or as the godoc describes it the ability to execute a single HTTP transaction, obtaining the Response for a
given Request.
Basically, what this means is being able to hook into what happens
between making an HTTP request and receiving a response.
In lay man terms, it's like middleware but for
an http.Client. I say this since round tripping occurs before the request is actually sent.
Although, it is possible to do anything within the
RoundTripmethod (as in like middleware for your HTTP handlers), it is recommended you don't inspect the response, return an error (nil or non nil) and shouldn't do stuffs like user auth (or cookies handling)..
Since http.RoundTripper is an interface.
All you have to do to get this functionality is implement RoundTrip :
type SomeClient struct {}
func (s *SomeClient) RoundTrip(r *http.Request)(*Response, error) {
//Something comes here...Maybe
}
And this is just keeping in line with other one method interfaces in the stdlib.. Small and concise.
Usecases
-
Caching http responses. For example, your web app has to connect to Github's API in other to fetch stuffs (with the trending repos one of it). In real life, this changes quite often but let's assume they rebuild that trending board once every 30 minutes and your app has tons of users. You obviously don't want to have to hit the api every time to request for the trending leaderboard. since it is always the same in a 30 minutes window and also considering the fact that API calls are rate limited and due to the high usage of your app, you almost always hit / cross the limit.
A solution to this is to make use of
http.RoundTripper. You could configure yourhttp.Clientwith a RoundTripper that does the following :-
Does the cache store have this item ?
- Don't make the
HTTPrequest. - Return a new response by reading the data from the cache into the body of the response.
- Don't make the
-
The cache store doesn't have this item (probably because the cache is invalidated every 31 minutes)
- Make the
HTTPrequest to the api. - Cache the data received from the api.
- Make the
-
You don't have to make use of a RoundTripper for this as (inside a handler) you can check the cache for the existence of an item before you make the
HTTPrequest at all. But with a RoundTripper implementation, you are probably distributing responsibilities properly<sup>[0]</sup>
-
Adding appropriate (authorization) headers to the request as need be... An example that readily comes to mind is google/go-github, a Golang client for Github's api. Some part of Github's api require the request be authenticated, some don't. By default, the library doesn't handle authentication, it uses a default HTTP client, if you need to be able to access authenticated sections of the api, you bring your own HTTP client along, for example with
oauth2protected endpoints.. So how does this concern Round tripping, there is this ghinstallation that allows you authenticate Github apps with go-github. If you look at it's codebase, all it does is provide anhttp.Clientthat implementshttp.RoundTripper. After which it set the appropriate headers (and values) in theRoundTripmethod. -
Rate limiting. This is quite similar to the above, maybe you have a bucket where you keep the number of connections you have made recently. You check if you are still in acceptable standing with the API and decide if you should make the request, pull back from making the request or scheduling it to run in future.
-
Whatever have you.. Maybe not.
Real world usage
We would be looking at caching HTTP responses with an implementation of http.RoundTripper.
We would be creating a server that responds to just one route, then a client package that connects to that server.
The client would make use of it's own implementation of http.Client
so we can be able to provide our own RoundTripper, since we are trying to cache responses.
So here is what it is going to look like,
- The client makes a request to the server.
- If the response for that url exists in the cache store ?
- Don't make the call to the server.
- Fetch the item from the store.
- Write it into the response and return it straight off.
- If the response for that url does not exist in the cache store
- Make the request to the server.
- Write the body of the response into the cache store.
- Return the response.
- If the response for that url exists in the cache store ?
This has been put up on github.
mkdir client server
We would be building the server first since it's implementation is quite simple
import (
"fmt"
"net/http"
)
func main() {
// server/main.go
mux := http.NewServeMux()
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// This is here so we can actually see that the responses that have been cached don't get here
fmt.Println("The request actually got here")
w.Write([]byte("You got here"))
})
http.ListenAndServe(":8000", mux)
}Then we would build the client package. This is the most interesting part, while it is quite long (130+ LOCs), It should be relatively easy to follow. I highly recommend you head to the github repo.
First of all, we would need a cache store.
Since this is a minimal project, a dictionary/map can help us get away ASAP.
We would create a http.Transport that implements http.RoundTripper but is also a cache store.
In real life you'd want to separate them from each other though.
func cacheKey(r *http.Request) string {
return r.URL.String()
}
type cacheTransport struct {
data map[string]string
mu sync.RWMutex
originalTransport http.RoundTripper
}
func (c *cacheTransport) Set(r *http.Request, value string) {
c.mu.Lock()
defer c.mu.Unlock()
c.data[cacheKey(r)] = value
}
func (c *cacheTransport) Get(r *http.Request) (string, error) {
c.mu.RLock()
defer c.mu.RUnlock()
if val, ok := c.data[cacheKey(r)]; ok {
return val, nil
}
return "", errors.New("key not found in cache")
}
// Here is the main functionality
func (c *cacheTransport) RoundTrip(r *http.Request) (*http.Response, error) {
// Check if we have the response cached..
// If yes, we don't have to hit the server
// We just return it as is from the cache store.
if val, err := c.Get(r); err == nil {
fmt.Println("Fetching the response from the cache")
return cachedResponse([]byte(val), r)
}
// Ok, we don't have the response cached, the store was probably cleared.
// Make the request to the server.
resp, err := c.originalTransport.RoundTrip(r)
if err != nil {
return nil, err
}
// Get the body of the response so we can save it in the cache for the next request.
buf, err := httputil.DumpResponse(resp, true)
if err != nil {
return nil, err
}
// Saving it to the cache store
c.Set(r, string(buf))
fmt.Println("Fetching the data from the real source")
return resp, nil
}
func (c *cacheTransport) Clear() error {
c.mu.Lock()
defer c.mu.Unlock()
c.data = make(map[string]string)
return nil
}
func cachedResponse(b []byte, r *http.Request) (*http.Response, error) {
buf := bytes.NewBuffer(b)
return http.ReadResponse(bufio.NewReader(buf), r)
}Then the main function where we bootstrap the program. We would set a timer to clear out the cache store, so we can make requests to the server, this is to enable us view which requests are being served from the cache or the original server.
func main() {
//client/main/go
cachedTransport := newTransport()
//Create a custom client so we can make use of our RoundTripper
//If you make use of http.Get(), the default http client located at http.DefaultClient is used instead
//Since we have special needs, we have to make use of our own http.RoundTripper implementation
client := &http.Client{
Transport: cachedTransport,
Timeout: time.Second * 5,
}
// Time to clear the cache store so we can make request to the original server rather than fetch from the cache store
// This is to replicate real expiration of data in a cache store
cacheClearTicker := time.NewTicker(time.Second * 5)
//Make a new request every second
//This would help demonstrate if the response is coming from the real server or the cache
reqTicker := time.NewTicker(time.Second * 1)
terminateChannel := make(chan os.Signal, 1)
signal.Notify(terminateChannel, syscall.SIGTERM, syscall.SIGHUP)
req, err := http.NewRequest(http.MethodGet, "http://localhost:8000", strings.NewReader(""))
if err != nil {
panic("Whoops")
}
for {
select {
case <-cacheClearTicker.C:
// Clear the cache so we can hit the original server
cachedTransport.Clear()
case <-terminateChannel:
cacheClearTicker.Stop()
reqTicker.Stop()
return
case <-reqTicker.C:
resp, err := client.Do(req)
if err != nil {
log.Printf("An error occurred.... %v", err)
continue
}
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Printf("An error occurred.... %v", err)
continue
}
fmt.Printf("The body of the response is \"%s\" \n\n", string(buf))
}
}
}To test this out, we have to build both programs - client/main.go and server/main.go.
Run them in their respective directories with ./client and ./server. You should get something like this
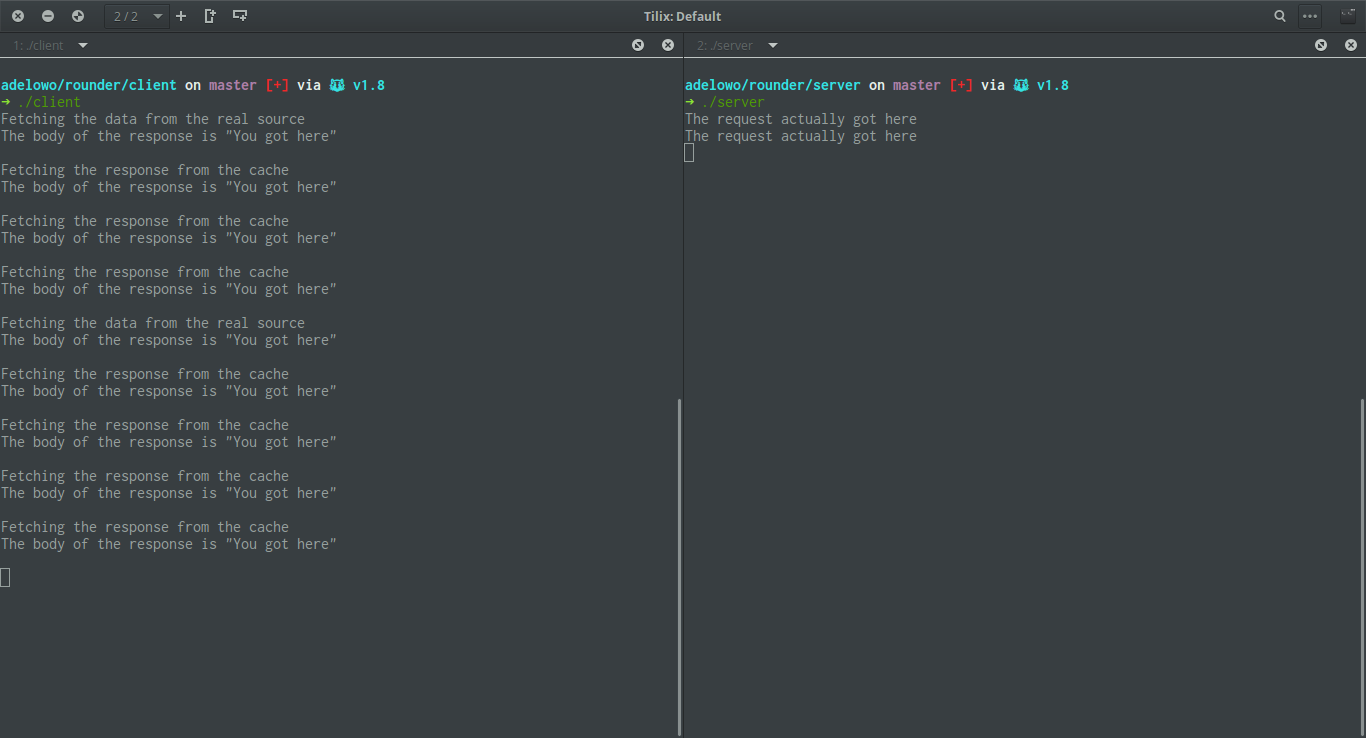
And watch what gets printed to the terminal, you would notice that some places say "fetching from the cache" while some would be "fetching from the server".
The most interesting part is if you look at the implementation of server/main.go,
we have a fmt.Println that would get executed only when the server is called,
you would notice that you only see that when the client
prints "Fetching from the server".
Another thing thing to note is that the body of the response stays the stay whether we hit the server or not.
Footnotes
[0] SRP ? What really is a responsibility ? The term is quite overloaded but hey SRP all things.